How to view a deleted page in a web archive
A web archive is a special service that stores data from all pages on the Internet on its server.
Even if the site ceases to exist, a copy of it will still live in this storage. The archive also stores all versions of Internet pages. Using a calendar, you can see what a particular site looked like at different times.
Deleted pages from VK can also be found in the web archive. To do this, you must perform the following steps.
- Go to https://archive.org/.
- In the top search block, enter the address of the page you need. Copy it from the address bar of your browser by logging into your remote VK account.
Using the Internet Archive, of course, you will not be able to write a message, nor will you be able to find out when the user was online. But you can even look at his latest added posts and photos.
Page found
If the page you are looking for is saved on a web archive server, it will give you the result in the form of a calendar chart. It will mark the days on which changes were made, information was added or deleted from the VK profile.
Select the date you need to see what the page looked like. Use the forward and back arrows to view the next or previous day, or return to the first search page and select the appropriate date in the calendar.
Page not found
It may happen that the required page was not found on the WayBackMachine website. This does not mean that you did something wrong, this often happens. It is possible that the user’s account was closed from search engines and third-party sites and therefore was not included in the archive. WayBackMachine is the most popular site, but it is not the only one of its kind. Try searching for other web archives in Yandex or Google. The page you were looking for could be saved on their servers.
Try your luck finding an archived version of the profile on these sites:
- archive.is;
- webcitation.org;
- freezepage.com;
- perma.cc.
Also, be sure to try to find a page on the Russian-language equivalent of https://web-arhive.ru/.
How to copy text: interesting ways and techniques
Just retype when I can’t copy the text from the site
As mentioned earlier, copy-protected text can simply be retyped using your chosen text editor. If the fragment of the desired text is relatively small, this method may come in handy. In addition, in most cases, when using text published on one of the Internet sites, you still have to use rating methods (written retelling of the text, which means that the passage will still have to be retyped by hand. In this case, the selected text can be immediately mentally changed and print the already “revised” version in the editor.
Other secrets: How to distribute Wi-Fi (Internet) without a router to a phone/other device
If a piece of text is too large and it will be difficult to retype it manually, you will have to use other methods to remove copy protection. Here are some of them.
How to copy text if it is not copied using HTML opening
In the control settings of the browser you are using, you need to find the “View” sub-item and select the “View HTML code” sub-item. In some modern browsers, these operations can be replaced with the key combination “ Ctrl + U". To speed up the search for the searched text, after opening the window with the HTML code, press the “Ctrl + F” keys and in the small search window that appears, enter the first few searched texts and press the “Enter” command.
After finding the desired text, all that remains is to select it with the cursor, copy it to the clipboard with the command “Ctrl + C” and paste it into the selected text editor using the keyboard shortcut “Ctrl + V”. After this, the text will be completely ready for further adjustment.
Take a screenshot and run it through an online text recognition service
If the desired text could not be copied using this method, this is most likely due to the fact that the text was saved as an image. To copy such text, you need to select the desired part of the page and take a screenshot of it in one of the graphic editors. There is a good, useful program for taking screenshots from your computer screen, if necessary, you can download it for free for yourself -. Or you can use the “Scissors” program for this purpose, which is installed on almost all computer operating systems.
Then, the resulting file must be passed through one of the free online services created for text recognition. All you need to do is attach a picture or screenshot, select the recognition language and start the process. We present some of them below.
This will help prepare the necessary text for further copying and intended use.
How to copy text using Microsoft Word (Macrosoft Word).
To do this, you need to copy the link address of the desired page, open Microsoft Office, click the “file” item and the “open” sub-item. After that, in the opening window that appears, you need to insert https://... of the desired page and select the “open” command again. In response to any Word warnings, you must click the “OK” button, thereby ignoring the username and password prompt. After this, all the information from the required copy-protected page will be available to you for editing and use.
Let's see what the page looked like before
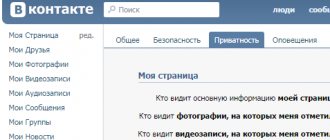
My VKontakte page: how to log into social media.
VK network without entering a password and what to do if you can’t log in. First of all, it should be noted that viewing an early copy of a page, be it an existing or already deleted user account, is possible only when the privacy settings do not limit the operation of search engines. Otherwise, third-party sites, including search engines themselves, cannot cache the data for later display.
Read more: How to open a VK wall
Method 1: Google Search
The most well-known search engines, having access to certain VKontakte pages, are able to save a copy of the profile in their database. At the same time, the lifespan of the last copy is very limited, until the profile is re-scanned.
- Use one of our instructions to find the user you need on Google.
Read more: Search without VK registration
Among the results presented, find the one you need and click on the arrow icon located under the main link.
From the drop-down list, select “Saved copy”.
You will then be redirected to the person's page, which looks exactly like the last scan.
Even if you have active VKontakte authorization in your browser, when viewing the saved copy you will be an anonymous user. If you try to log in, you will encounter an error or the system will automatically redirect you to the original site.
You can only view the information that is loaded along with the page. That is, for example, you will not be able to view subscribers or photos, including due to the lack of authorization.
Using this method is not practical in cases where you need to find a saved copy of a very popular user's page. This is due to the fact that such accounts are often visited by third parties and therefore are much more actively updated by search engines.
Method 2: Internet Archive
Unlike search engines, a web archive does not impose requirements on the user page and its settings. However, not all pages are saved on this resource, but only those that were added to the database manually.
The main negative factor of this method is that any information on the page, with the exception of manually entered data, is presented in English. You can avoid this problem by using the following service.
Method 3: Web Archive
This site is a less popular analogue of the previous resource, but it copes with its task more than well. In addition, you can always use this web archive if the previously reviewed site is temporarily unavailable for some reason.
- Having opened the main page of the site, fill in the main search bar with a link to your profile and click the “Find” button.
After this, the “Results” field will appear under the search form, where all found copies of the page will be presented.
In the “Other dates” list, select the column with the desired year and click on the name of the month.
Using the calendar, click on one of the numbers found.
Once the download is complete, you will be presented with a user profile corresponding to the selected date.
As in the previous method, all capabilities of the site, except for directly viewing information, will be blocked. However, this time the content is completely translated into Russian.
You can also refer to another article on our website that talks about the possibility of viewing deleted pages. We are completing this method and article, since the material presented is more than enough to view an early version of the VKontakte page.
Describe what didn't work for you. Our specialists will try to answer as quickly as possible.
r-tools.org
The first thing that catches your eye is the design of the site. Guys, it's time to update!
Pros:
- Suitable for parsing sites that have few html pages and a lot of other types of resources. Because they calculate the price based on html pages
- the ability to abandon the site if the quality is not satisfactory. After the system has downloaded the site, you can make a preview and refuse if the quality is not satisfied, but only if you have not yet ordered archive generation. (I haven’t tested this function personally, and I can’t say how well the preview is implemented, but in theory it’s a plus)
- Implemented quick integration of the site with the SAPE exchange
- Interface in Russian
Minuses:
- There is demo access - this is a plus, but I tried to do 4 tasks and did not get any results.
- High prices. Parsing 25,000 pages will cost 2,475 rubles. , and for example on Archivarix $17. It is necessary to take into account that r-tools considers html pages and archive files. But even if out of all the files for $17 only half of the html page is, r-tools is still more expensive. (I need to make a reservation that I calculated at $=70 rubles. And a situation is possible when r-tools will be profitable, I wrote about this in the pros)
Possibility of using web archives
VKontakte my page
Saved History Features
Now everyone knows what a web archive is and what sites provide services for saving copies of projects. But many still do not understand how to use the information presented. The capabilities of archival data are expressed as follows:
- Choosing a domain name. It's no secret that many webmasters use already upgraded domains. It is worth understanding that experienced users track not only target parameters, but also the history of previous use. Every network user wants to know what they are purchasing: whether there were previously prohibitions or sanctions, whether the project was subject to filters.
- Restoring a site from archives. Sometimes a disaster happens that threatens the existence of your own project. The lack of timely backups in the hosting profile and an accidental error can lead to tragedy. If this happens, don’t be upset, because you can use the web archive. We'll talk about the recovery process below.
- Search for unique content. Every day, sites filled with content die on the Internet. This happens with particular consistency, which is why a huge flow of information is lost. Over time, such pages fall out of the index, and a resourceful webmaster can borrow the information for a personal project. Of course, there is a search problem, but that is a secondary concern.
We've looked at the main features that web archives provide, now it's time to move on to a more detailed study of individual elements.
Restoring a website from a web archive
Recording in the web archive for 2011–2016
No one is immune from problems with websites. Most of them are solved using backups. But what if there is no saved copy on the hosting server? Use the web archive. To do this you should:
- Go to the specialized resource we talked about earlier.
- Enter your own domain name into the search bar and open the project in a new window.
- Choose the most successful photo, which is located closer to the problem date and has a full-fledged view.
- Fix internal links to direct ones. To do this, use the link “https://web.archive.org/web/any_sequence_number_id_/Site name”.
- Copy lost information or design data to be used for recovery.
Note that the process is somewhat tedious, given the speed of the archive. Therefore, we recommend that owners of large web resources make backups more often, which will save time and nerves.
We are looking for unique content for our own website
Unique content from a web archive
Some webmasters use an interesting way to obtain new content that no one needs. Every day hundreds of sites go into oblivion, and information is lost along with them. To become a content owner, you need to do the following:
- Enter the URL into the search bar.
- On the domain name auction website, download files with the name ru.
- Open the received files using Excel and begin selection based on the availability of design information.
- Enter the projects found in the list on the web archive search page.
- Open the snapshot and access the information flow.
We recommend monitoring content for plagiarism, this will allow you to find truly worthy texts. And that's all! Now everyone knows about the possibilities and methods of using a web archive. Use knowledge wisely and profitably.
What is the Wayback Machine and Internet Archives
My VKontakte page
In this article we will look at Web Archives of sites or Internet archives: how to search for information deleted from sites, how to download sites that no longer exist and other examples and use cases.
The principle of operation of all Internet Archives is similar: someone (any user) specifies a page to save. The Internet Archive downloads it, including text, images and design styles, and then saves it. Upon request, saved pages can be viewed from the Internet Archive, and it does not matter if the original page has changed or the site is currently unavailable or has ceased to exist altogether.
Many Internet Archives store multiple versions of the same page, snapshotting it at different times. Thanks to this, you can trace the history of changes to a site or web page throughout all the years of its existence.
This article will show you how to find deleted or changed information, how to use Internet Archives to restore sites, individual pages or files, as well as some other use cases.
Wayback Machine is the name of one of the popular web archive sites. Sometimes the Wayback Machine is used synonymously with "Internet Archive".
Reading comments in the source code
VKontakte my page: login without password, login and phone number for free
We go to the site, press Shift + Command + U (or select Show page code from the menu). First, we look through the HTML code for fake comments with names and nicknames. For example: “BigFatNagibator, please check this place!” Along the way, we are looking for js scripts that were written by the site owner specifically for this resource. It is possible that they may contain the solemn inscription “Created by Sasha Petrov. Irkutsk" and a link to his Github profile.
The effectiveness of all these methods depends largely on your perseverance and ingenuity. If the site owner is not completely paranoid and lives an online life, then there must be a thread that will help find him.
If you don’t need to look for anyone, but you have a project whose ownership you would like to hide, then I recommend checking all the points in the article to determine the degree of difficulty in identifying your identity. Maybe you'll be surprised.
iPhones.ru
Another manual for novice scouts. Information about the domain owner is confidential and is provided by the registrar only at the request of the authorities. But there are several possible ways to find her out. We will talk about them in this article. Why is this necessary: to find justice for the person who is blatantly stealing your content, to assess the solvency of the site owner before making him an offer...
Student programmer website
Home pages “I’m Misha, I live in New York, I have a cat” - the basis of the Russian-language Internet of those years. Such sites were created by emigrants who were looking for communication with former compatriots. Before 1997, there were still few personal pages of Russian residents.
For example, 22-year-old Yuri Blazhevich from MIPT posted on the website his resume and programs he had written for creating 3D graphics. There he talked about his interests and collected links to useful Internet sites.
A few years later, the guy was able to make a good career and became the leading programmer in the popular game Blitzkrieg 2. But, unfortunately, he passed away in 2007.
Page saved: October 7, 1997.
How to check site history
- The most popular site for checking the history of a domain is whoistory.com, which is a database of Runet sites. The domain address is entered in the Whois field, after which information about the current owner appears. This service has been operating for 10 years, is open access and absolutely free.
- Using the global archive of sites archive.org, you can look at the history of the site itself - if there is no data in the calendar that opens, then the site has a clean past. If you select a specific date in the calendar, you will be able to see what the site was like at that time.
- A similar service is offered by the Reg.ru service, where you can easily and quickly find out the history of a site, obtain information about the previous owner and find out the cost of a domain. To do this, just enter the name of the site in the query line and select the option for the required information.
- Yandex offers a very convenient service with which you can make sure that the domain you plan to purchase is not blacklisted by search engines. To do this, you need to put the site in the queue for indexing by adding its address to webmaster.yandex.ru. It is worth buying a domain if it is put in a queue for indexing, otherwise it is better not to make such a purchase. It is almost impossible to determine whether any filters are applied to a domain. If a site is not included in the index for a long time, which indicates a ban, or only the main page is indexed, which indicates the likelihood of AGS, then experts recommend writing to Yandex technical support.
Is it possible to restore a site from a web archive?
If you lose data, you can restore your site using the site https://webarchiveorg.ru/. To do this you need:
- enter URL;
- select the desired year, month and day;
- Click the “Restore site” button.
The service is paid, so it is recommended that you familiarize yourself with the tariffs before restoring. The exact cost depends on the number of sites and its pages.
Internet Explorer
Internet Explorer has long been the first thing that users think of when wondering how to view their browsing history.
The quickest way is to click on the star in the same upper right corner and select the “Log” tab with links to lists of sites visited today, yesterday, last week, 2 and 3 weeks ago. Here you can delete them using the right button.
You can delete your browsing history by clicking on the gear next to the asterisk in the upper right corner and selecting “Internet Options.” In the “Browsing history” section there is a “Delete...” button, by clicking on which we call up the “Deleting browsing history” window, where you can check the boxes to specify what you intend to say goodbye to (cookies, log, web form data, etc. ).
A link to the Internet Options panel is also located in the Tools menu at the very bottom, and the top link (“Delete browsing history”) will take you to the familiar “Delete browsing history” window, where we will be asked to select deletion options. In addition, here we can study in more detail how to delete your browsing history by clicking on the link below (“More about deleting…”).
Why do you need a separate program to open an archive?
An archive is a special file in which any amount of different information can be stored. The advantages of storing files in an archive file are obvious - they take up significantly less space on your computer compared to the amount required to store non-archived files. Therefore, downloading them from the Internet will take much less time. Also, information in the archive can be reliably protected from prying eyes if it is under a password. The information contained in the archives is written in the form of a special code and therefore, to open them, programs are needed that can decipher this code. The most popular utilities for working with archives are Win Rar and 7Zip. Extensions -zip, rar, 7-zip.
Step-by-step opening plan using 7 zip as an example
1.If the 7 zip program is installed on your computer, then in order to open the archive you must: 1.1. Right-click on the archive, select 7Zip in the context menu that appears, and then select the first line “Open archive”.
Select in the context menu - open archive
When the archive opens, a list of files contained in it will appear.
1.2. To extract files, you need to mark the files and click the “Extract” button.
1.3. The window that appears indicates the path, the final folder of which will be the location where the files are extracted. To change the extraction location, click the “…” button.
Specify the folder to extract the archive contents
In the window that appears with a folder tree, you need to select the folder into which you want to extract. There is also a “Create Folder” button, which allows you to create a new folder in the desired location.
Specify the folder for extraction
1.4. After selecting the extraction folder, you need to click “Ok” (Figure 5). 1.5. Next, to unzip you need to click “OK”. The file is extracted to the specified location.
If you need to extract the file to the same folder in which the archive is located
2.1. Mark the archive and right-click, select 7Zip in the menu that appears, and then Extract Here.
Extract to archive folder
2.2. The files have been extracted.
New version of VKontakte on your phone
The new version refers to the full version of the site that people use on computers and tablets. This does not apply to the VK application for phones, which is developed and updated separately (see: How to log into VK from a phone).
Not everyone likes the new version of VKontakte. Many people demand to return the previous version, which they consider more convenient. Some argue that the new design is too similar to Facebook and even Odnoklassniki. Users even created an online petition demanding that the old version be preserved and given the “right to choose.” Most likely, this will not affect anything. Online petitions are often created for various reasons and thanks to them, information is disseminated very widely. But in reality, the petition has never helped anyone. When the noise subsides, everyone forgets about her.
VKontakte laughed at its users who promised to leave if they did not return the old version. A month after their promise, they still continued to sit on VK (look at them).
It is known that some people always greet any major update with hostility, since changing old habits is too painful for them. But over time they calm down.
Why is it important? When you express your opinion, it will become easier, you will release your negativity. True, 92% of people will not read this, but will immediately look for a hole where they can write
Congratulations if you're reading this! If you really want to contact VKontakte employees and ask them to return the old version, try contacting their support service.
Deleting the list of visited sites
If you do not want anyone to know about your “walks” on the Internet, you can delete the list of links to sites you visit. If you don’t know how to delete your browsing history from your computer, read below.
There are several ways to clear your browsing history. Of course, an inconvenient option that requires time is to remove each link individually from the Journal. However, browsers provide a simpler way to clean up.
Google Chrome
Go to “Tools”—“Deleting data about viewed documents.” Specify the deletion depth in the drop-down list. Next to “Clear history”, check the box and click delete.
Clear history in Google Chrome
You can use the combination Ctrl+Shift+Del.
Firefox
In this browser, find the “Tools” section, on the “Settings” line. In the window that opens, go to the “Privacy” tab - “Clear immediately”. A new “Delete unnecessary data” window will appear. Make sure that there is a checkmark on the item indicating the visit log. Place marks on what you want to clear, then click “Delete.”
Explorer
In IE, browsing history is called "Browser History". The path to it is through the menu, the “Service” section, there is a line “Delete history”, then click on “Delete history”.
Delete browser history in Internet Explorer
Opera
In the browser menu, go to “Settings”, find the “Delete personal data” option. The default settings are hidden in the settings, expand them by clicking “Detailed settings”. Go to the item “Clearing the history of visited pages”, look through everything carefully so as not to destroy what you need.
Safari
Safari has a separate section in the browser's History menu. Go to it, there you will see a link to delete information.
Clear history in Safari
Yandex
In your browser, click on the icon next to the address bar that resembles a wrench. Next, go to “History”. You will see a list of visited sites, check the boxes next to those you want to delete, and click the corresponding button.
Online services for copying simple websites
There are services on the Internet that copy the landing page, clean it and change it. You need to specify the target site, and the service will download it and clear the copied page of unnecessary code and foreign links. The client will receive a new one-page website in the form of a ready-made archive for uploading to the hosting.
Examples of such services:
copysta.ru - you indicate the address of the “donor” and the service completely downloads the landing page, clears it of unnecessary code, changes contacts, application forms are rearranged to the customer’s email, and an admin panel is installed to manage the landing page on the customer’s hosting. Cost of services: 1,500-3,000 rubles. The most expensive tariff includes editing content, styles, replacing images in order to make the new landing page unique;
7lend.club - this service offers services from simple downloading to code cleaning, installation of counters and customer forms and unique content. Cost from $8 to $50 per landing page;
copyland.pro – offers to make a copy of a landing page of any complexity, clearing old contacts, links, web statistics counters and rebuilding details, forms and counters for the customer. Cost of services from 500 rubles; xdan.ru/copysite/ allows you to make a local copy of the site. At the same time, you can clear HTML of counters, replace links or domains in links, replace specified words, 11 settings in total. The minimum subscription is 75 rubles for 24 hours.
These are just examples of services. You can find hundreds of these if you search.
Disclaimer: The author or publisher has not published this article for malicious purposes. All information posted was taken from open sources and is presented for informational purposes only and does not contain a call to action. Created for educational and entertainment purposes only. All information is aimed at protecting readers from illegal actions. The visitor assumes all possible damages caused. The author performs all actions only on his own equipment and on his own network. Don't repeat anything you read in real life. | Also, if you are the copyright holder of the material posted on the pages of the portal, please write to us via the contact form with a complaint about the deletion of a certain page, and also read the instructions for copyright holders of materials. Thanks for understanding.
How to use web archive?
Form for searching information on Peeep.us
As noted above, a web archive is a site that provides a certain kind of search service in history. To use the project, you must:
- Go to a specialized resource (for example, web.archive.org).
- Enter information for the search in the special field. This could be a domain name or a keyword.
- Get relevant results. This will be one or more sites, each of which has a fixed crawl date.
- By clicking on a date, go to the corresponding resource and use the information for personal purposes.
We’ll talk about specialized sites for searching for historical records of projects later, so stay with us.
Working with drop and released domains
Drop domains are domains that are intercepted (registered) at the moment of their release. As a rule, a good domain is quite difficult to intercept. A good domain means a domain that has trust, expressed in the presence of a high-quality link mass or high traffic. After interception, the site must be immediately hosted. But where can you get the files or the resource itself if you don’t have the source? That's right, restore what you have from the archive and use it either as a temporary solution, or put up advertising and receive passive income.
The same thing applies to released domains, with the exception of a simpler registration procedure, because the domain name has already been released.
If traffic to such a web project is restored, then you can place advertising banners from affiliate programs like Google.Adsense or YAN and enjoy passive income. Some sell links.
How to view Yandex browser history
Any user can view their visits to sites. This is exactly why the “Visit History” section was created. It's very easy to get there.
To do this on your computer you need the following:
- Open the menu by clicking on the three lines in the upper right corner.
- Now we need to find the "History" line.
- A list of recently visited sites will open next to it. Clicking on a similar line will open the full list.
- To search, you can use the command Ctrl + H.
Pages are sorted by date and time. Scrolling to the very bottom of the page, the line “Previously” will appear. It is designed to access earlier information.
If you move the mouse cursor to the site line, an arrow will appear, and when you click on it, additional functions will open. This includes viewing all visits associated with this resource or deleting this entry.
Before moving on to the next section, I suggest you take a relaxing moment. Let's listen to your favorite music on your phone. To do this, we need to download them to the smartphone.
How to open archived records from a computer
If a person from a computer wants to find an archive on Instagram, he is unlikely to understand where. And all because the PC version does not provide such an option. The Instagram service for PC has very limited functionality. But don’t despair, it’s also possible to view an archived Story or post from your computer. For this you will need auxiliary programs. For example, this is Bluestacks. To use it, you need to do the following:
- first find and download the original version of the Bluestacks Android emulator for PC;
- Use the emulator to find the Instagram service and install it;
- then log into the Instagram social network through the emulator. You must enter your username and password to log into your profile. An interface similar to the original Instagram will open;
- find the profile icon in the lower right corner;
- On this page, next to the menu icon, the archive will be located. Its icon is a standard watch with an arrow;
- if it’s not there, then you need to enter the menu hidden behind three horizontal stripes;
- find “Archive” in the drop-down menu;
- choose what to watch – archived publications or stories.
Through this program on your computer you can view all records, starting from the very first date of profile creation.
If the old page was linked to the same number
Important: if you registered a new VK page on the same phone number as the old one, then now the old page is no longer linked to this number. Maybe you think that now both pages are on the same number, but this is not so
Only one page can be linked to one number, and the number was unlinked from the old page when you created a new one. You just didn’t pay attention to what the site was telling you.
What to do in this case? There are several ways to solve the problem, see here: What to do if you created two pages for one VKontakte number. Each person is allowed to create only one page on VK, and if you lose access, you need to restore it, and not create a new page (and at the same time new problems).
And my old page and new one are tied to the same phone number!
There is a difference between login and linking a phone. Two pages can be registered to the same number (that is, have the same login), but both cannot be linked to the same number. When you linked a new page to your phone, the old one immediately unlinked from it. Like this! Now you won’t be able to restore access to it by phone, and you’ll have to use other methods. More details here: What to do if you created two pages for one VKontakte number.
Computer company website
How to view VKontakte history
One of the most fashionable and profitable activities at that time was to have a business related to computers. If a company selling tights at that time could live quietly without a website (there was no one to log in anyway), then IT companies needed their own page on the Internet “due to status.”
Such sites had two typical characteristics. The first is a welcome page with a huge logo, contacts and links to switch to versions of sites in different text encodings. If the krakozyabry turned into the inscription “Do you see Russian letters?”, then the encoding was chosen correctly and you can look at the remaining pages.
Also, such sites always had a section indicating the people who worked on its creation (even if it only has two pages). In this example, it is called web team ingredients, and Mikhail Kornev introduces himself as Misha Korneff. It is also indicated that Sergey Golev was engaged in Digitizing and Major Image Processing (scanned photos).
Page saved: December 19, 1996.
How to install 301 redirect
Now that we've discussed what a 301 redirect is, its importance, and when you should use it, let's take a look at the most common methods for setting up a 301 redirect.
301st redirect using .htaccess file
In the vast majority of cases, the web server is configured using the so-called .htaccess file. This is a simple text file that is located in the root directory of your site. To set up a 301 redirect, you need to place a .htaccess file in the root directory (if this file does not already exist). You can create or edit the .htaccess file using any plain text editing tools such as Notepad, Sublime or Nano.
We'll start with a simple example, namely renaming a page on your website. For example, if you want to change the page URL from:
https://www.example.com/old.html
on the:
https://www.example.com/new
To make the old page redirect to the new one, you need to add the following code to your .htaccess file:
redirect 301 /old.html https://www.example.com/new
Here's an explanation of what the code above means:
- A “301 redirect” tells search engines (and browsers) that your page has been moved permanently.
- "/old.html" - indicates the old location of the page.
- "https://www.example.com/new.html" is the new location of the page to which the web server should redirect visitors.
It's important to note that if you're moving multiple pages, you'll need to make redirects for each of the pages you're moving. Creating a unique string for each page is recommended as the safest approach if you want your commands to be picked up by search engines
301 Redirect: WordPress
If you have a WordPress site, then you can use any of the available plugins to create a redirect. For example, a plugin like Redirection allows the user to enter the old URL, then the new URL and an anchor - and now you have a 301 redirect. This simplifies the redirection process and reduces time. In addition, with this plugin, you can immediately set up redirect groups.
Who is Tim Berners Lee
Berners Lee has the ideal image of a significant figure in the IT industry.
He has been familiar with technology since childhood. His parents were mathematicians and were involved in the development of one of the world's first computers, the Mark I.
While studying at King's College Oxford, Tim staged a hacker attack on the school. For this, he was banned from using university desktops.
Breaking the grid before it became mainstream.
Since the launch of the Web, the Briton has insisted that the Internet should be public and decentralized.
He didn't even try to make money on the rights to the technology and refused to patent it.
“If this technology had been proprietary and I had complete control over it, it probably wouldn’t have taken off. It is impossible to offer something that would be publicly available, and at the same time you retain control over it,” the scientist said.
Tim Berners Lee on the left, Robert Cayo on the right
In addition to being involved in the creation of the first website, Tim Berners Lee is considered the inventor of URIs, URLs, HTTP and HTML. These are the technologies that can be found at info.cern.ch.
More precisely, Berners Lee came up with:
- HTML markup language for creating web pages
- HTTP protocol for data transfer on the Internet
- system of unified URL resource addresses for searching a document or page
These technologies are still used on the Internet today.
Site's home page
The goal of the project is commonplace for epoch-making technology at the initial stage - to simplify the work of the team. Mark Zuckerberg then created Facebook to make it easier for him and his classmates to communicate with each other.
CERN rejected the idea, but Berners Lee persisted and continued to develop the site, now in a team with Robert Caillot.
This is what CERN, the European Organization for Nuclear Research, the world's largest high-energy physics laboratory, used to look like.
The scientist proposed making hypertext available simultaneously to several computers connected to the Internet.
“I was frustrated because different computers contained different information. And to access it from multiple sources, you need to use multiple computers,” said Berners Lee.
NeXT. The computer on which the first website was created.
The Briton also had a larger task. People from universities all over the world came to CERN and brought with them computers with all kinds of software. The problem was the impossibility of using one program on computers with different types of software.
Berners Lee sought her solution. Initially, he thought about creating a series of programs that took information from one system and converted its format for display in another.
But optimizing programs for each software is time-consuming, energy-consuming and expensive. The Briton chose a different method: simply giving access to information to everyone at once.
Usenet interface.
Before the creation and development of the Internet, the computer network Usenet was popular.
It was also used for communication and file transfer. But the principle was different: the difference was that Usenet consisted not of pages, but of news groups and worked using the NTTP protocol.
By the way, this network became the foundation for the development of the web. It was here that the first online communities appeared. Its users introduced the concepts of “nickname”, “smile”, “flood”, “trolling” and other terms without which we cannot imagine the Internet community.
Berners Lee advocates reorganizing the Internet.
Today Berners Lee actively advocates for the openness of the Internet. He is skeptical about the localization of personal data of users of his country and the ideas of a sovereign Internet.
Tim says that any division of the network into segments is a very bad idea. The reason for the rapid development of the Internet was that the Internet was non-state, open and public
How to register without a phone number
You can register in Contact without a phone number. For this purpose, there is such a service on the Internet as a virtual number. This is a temporary phone without a SIM card. You can receive an SMS with an activation code, and this is exactly what we need to create a new page.
The principle is as follows:
- We get a virtual phone number;
- We print it when registering in VK;
- We receive an SMS with a code and enter it on the website.
Free virtual numbers
There are services where they give out free phones for receiving SMS. They come in several types:
- Sites with public numbers are pages where currently available telephone numbers are published. These are resources such as freeonlinephone.org, receivesmsonline.net, receive-sms-online.com, sms.sellaite.com, onlinesim.ru and others. Everything is simple there: you click on the number, and a list of SMS messages that were sent to it opens.
- Sites with registration - you must first register on them and after that a number for SMS will be indicated in your personal account. And here, in your personal account, you can read received messages. These are resources such as twilio.com, sonetel.com, pinger.com and textnow.com.
- Android applications are phone programs that allocate virtual numbers to users. To get a free number, you need to install the application on your Android smartphone and register in it. The most popular applications: Swytch, Telos, Text Me.
In practice, I tried every free site and every application. I spent several days on this, but never received the treasured SMS with the code.
Some of the numbers are busy, that is, pages are already registered on them. For some reason Contact does not accept other phones. And they don’t receive the third SMS. I see only one option: monitor sites with public numbers and, as soon as a new phone appears, quickly register a page for it.
Note: if you read other instructions for registering on VKontakte without a phone number, they often recommend the pinger.com service. Previously, it was actually possible to register through it, but this method has not worked for a long time. Either the issued number does not work, or SMS messages are not being received.
Paid virtual numbers
You can buy a one-time virtual number on the Internet. This is a temporary phone that is issued online for a certain period of time (usually 15-20 minutes). You can receive a code for creating a VK account.
What is Web Archive?
This is a free service where the histories of many Internet resources are collected - their archived copies. Moreover, we are not talking about screenshots, but about full-fledged pages with images, working links and styling.
Obtaining information about a particular domain involves not only an interesting pastime tracking the evolution of a web project, but also the opportunity to:
- find out the topic of the site - the Internet archive demonstrates the content, making it easy to determine the niche of the project;
- see what the site looked like before - this is a godsend for hunters of used domains;
- determine whether the analyzed domain has been registered before - a useful tool for those who value the “sterility” of the domain or to avoid sanctions from search engines;
- restore your site if for some reason you didn’t make a backup.
- finding unique content is a time-consuming task that can give you dozens of free articles;
- see deleted text from bookmarks - the chances of finding the desired page are quite high.